环境部署
环境安装
jieba 是高效的中文分词工具,支持词性标注和关键词提取;neo4j 是用于与 Neo4j 图数据库交互的 Python 驱动,支持复杂图形数据查询;numpy 提供多维数组操作和数值计算功能,是数据处理的基础工具;torch 是 PyTorch 深度学习框架,支持动态计算图和 GPU 加速,用于深度学习模型的构建与训练;transformers = 4.46.3 是 Hugging Face 提供的 NLP 库,支持预训练模型的使用与微调。
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
neo4j 图数据库安装
知识图谱数据需要存储于图数据库之中,由于 Neo4j 是基于 Java 的图数据库,运行 Neo4j 需要启动 JVM 进程,因此必须安装 JAVASE 的 JDK。本次实验使用 jgk17.0.8 版本,与 neo4j5.11.0 版本。
JDK 下载地址:https://www.oracle.com/java/technologies/downloads/?er = 221886#java21
下载后直接点击安装,新版本会自动设置环境变量
验证安装:
java -version

neo4j 图数据库下载地址:https://neo4j.com/deployment-center/
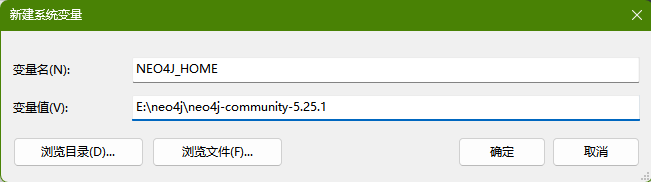
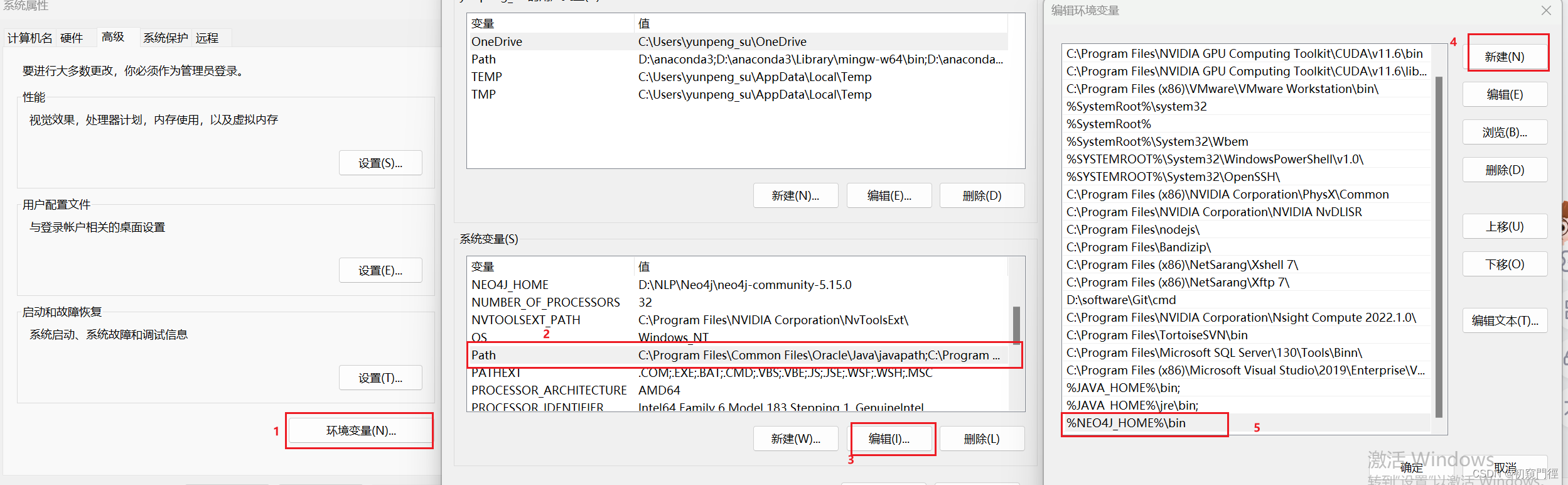
解压到自定义英文文件夹,新建环境变量 NEO4J_HOME,变量值就是刚才解压下载文件的地址。在系统变量区的 Path 中新建变量:%NEO4J_HOME%\bin
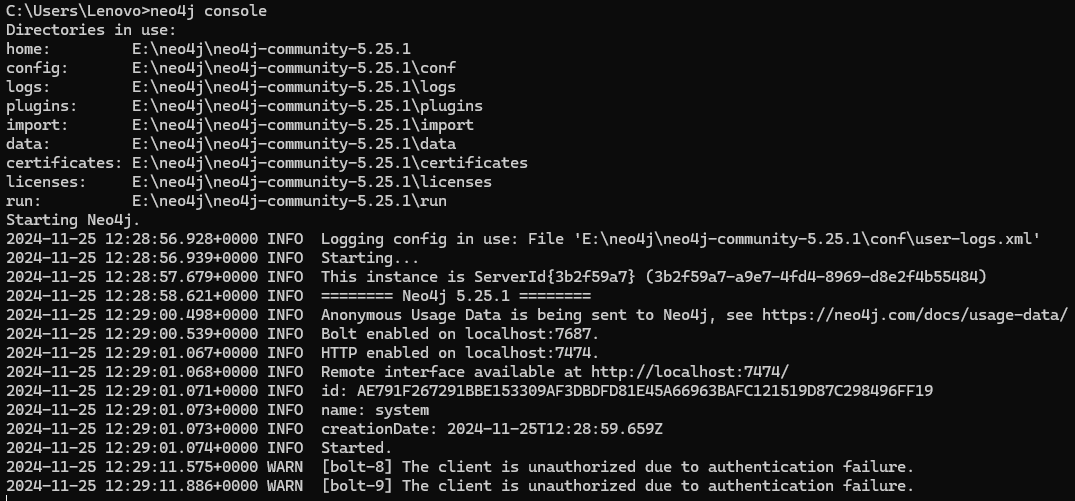
启动服务验证安装:
neo4j console
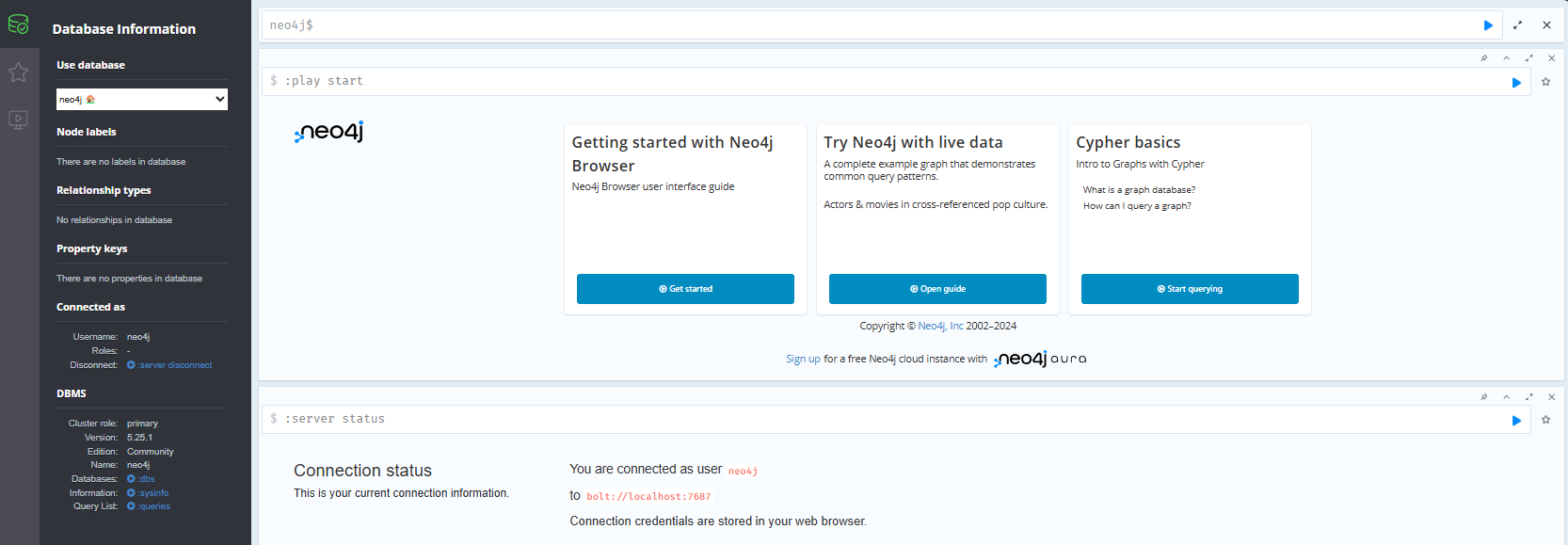
按住 Ctrl 键点击 http://localhost: 7474/,重置密码(默认密码 neo4j),进入数据库页面,安装成功。
数据说明
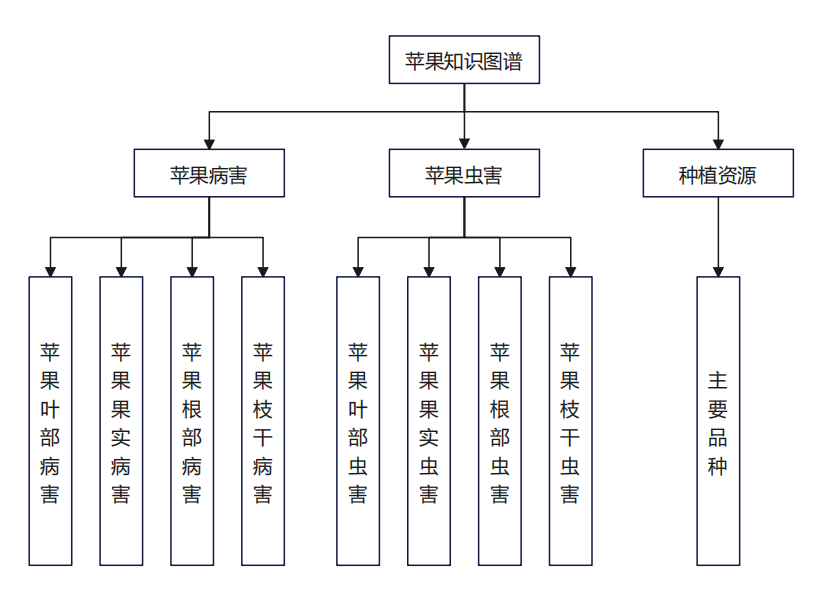
apple_entities_relations.csv 中存储数据有两种。一种结构为 <实体,关系,实体>,例如 <'苹果枝干虫害' , '包括' , '梨小食心虫'>。知识图谱总体结构如图所示。另一种结构为 <实体,属性,属性值>,例如 <'苹果白纹羽病' , '病症' , '地上部叶片变小、黄化,叶柄和中脉发红,枝条节间短;'>。所有数据来源为李林光《苹果实用栽培技术》,在构建知识图谱时可以根据书籍自行定义,也可以训练模型进行实体和关系的抽取。知识图谱结构如图所示。
templates 文件夹下有问题模板 question_templates.json 和回答模板 answer_templates.json,均以 json 形式存储。在意图识别过程中与用户输入文本进行对比匹配,提取用户问题中的意图信息。所有模板需要根据实体关系自行定义。在问题模板中,键“发病原因”表示意图,值为字符串的列表,每个字符串都是一个可能的问题,用于询问某种病害的发病原因。在回答模板中,键“发病原因”与问题模板相对应,值为一个字符串,其中 {} 是占位符,用于在生成答案时被替换为具体的病害名称和发病原因。
a+b =\hat{c}
//question_templates
{
"发病原因": [
"病害的发病原因是什么?",
"病害发病的因素有什么"
],
}
//answer_templates.json
{
"发病原因": "{}的发病原因是:{}"
}
知识图谱构建
代码通过调用 build_knowledge_graph_from_csv 函数,将 CSV 文件中的实体和关系数据导入 Neo4j 数据库,完成知识图谱的构建;随后,调用 process_entity_frequencies 函数,统计 CSV 文件中实体的出现频次,并将结果写入 apple.txt 中。
# 示例调用
if __name__ == "__main__":
# 配置数据库连接信息和文件路径
NEO4J_URI = "bolt://localhost:7687"
USERNAME = "neo4j"
PASSWORD = "123456"
CSV_FILE_PATH = "apple_entities_relations.csv"
OUTPUT_FILE_PATH = "apple.txt"
# 调用主函数构建知识图谱
build_knowledge_graph_from_csv(CSV_FILE_PATH, NEO4J_URI, USERNAME, PASSWORD)
# 统计实体频次并写入文件
process_entity_frequencies(CSV_FILE_PATH, OUTPUT_FILE_PATH)
KnowledgeGraph 类用于与 Neo4j 数据库交互,提供构建知识图谱的功能,包括创建实体、关系和属性。通过 init 方法初始化数据库连接,接受 URI、用户名和密码作为参数,并通过 GraphDatabase.driver 建立驱动实例;close 方法用于关闭数据库连接,释放资源。create_node_relationship 方法实现两个实体及其关系的创建,接收实体名称和关系类型作为参数,利用 Cypher 语句确保实体和关系的存在。create_property_relationship 方法为实体添加属性及属性关系,将属性名和属性值作为独立节点,与实体通过关系相连。
class KnowledgeGraph:
def __init__(self, uri, user, password):
"""初始化 Neo4j 数据库连接"""
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def close(self):
"""关闭数据库连接"""
self.driver.close()
def create_node_relationship(self, entity1, relation, entity2):
"""创建实体和关系"""
with self.driver.session() as session:
session.run("""
MERGE (e1:Entity {name: entity1})
MERGE (e2:Entity {name:entity2})
MERGE (e1)-[:RELATION {type: relation}]->(e2)
""", entity1=entity1, relation=relation, entity2=entity2)
def create_property_relationship(self, entity, property_name, property_value):
"""
为实体添加属性关系
将属性名和属性值转化为独立节点,并通过关系与实体相连
"""
with self.driver.session() as session:
session.run("""
MERGE (e:Entity {name:entity})
MERGE (p:Property {name: property_name, value:property_value})
MERGE (e)-[:HAS_PROPERTY]->(p)
""", entity=entity, property_name=property_name, property_value=property_value)
build_knowledge_graph_from_csv 函数用于从 CSV 文件构建知识图谱,连接到指定的 Neo4j 数据库,并根据 CSV 中的数据创建实体、关系和属性。首先,函数通过创建 KnowledgeGraph 类的实例来初始化与 Neo4j 的连接。接着,函数尝试打开 CSV 文件并读取内容,使用 csv.reader 按制表符(\t)分割每行数据。在每行数据中,如果有三个元素,分别表示两个实体和它们之间的关系,函数根据关系类型决定是创建普通的实体关系(通过 create_node_relationship 方法)还是将关系转化为实体属性关系(通过 create_property_relationship 方法)。完成图谱构建后,函数会关闭数据库连接并输出构建完成的消息。如果在处理过程中出现任何异常,错误信息会被捕捉并输出。
def build_knowledge_graph_from_csv(csv_file, uri, user, password):
"""
从 CSV 文件构建知识图谱的主函数
参数:
csv_file (str): CSV 文件路径
uri (str): Neo4j 数据库 URI
user (str): 数据库用户名
password (str): 数据库密码
"""
graph = KnowledgeGraph(uri, user, password)
try:
with open(csv_file, "r", encoding="utf-8") as file:
reader = csv.reader(file, delimiter="\t")
for row in reader:
if len(row) == 3:
entity1, relation, entity2 = row
if relation == "包括":
graph.create_node_relationship(entity1, relation, entity2)
else:
# 替换为使用关系存储属性
graph.create_property_relationship(entity1, relation, entity2)
else:
print(len(row))
print(f"数据格式不正确: {row}")
print("知识图谱构建完成!")
except Exception as e:
print(f"构建知识图谱时出错: {e}")
finally:
graph.close()
process_entity_frequencies 函数用于从 CSV 文件中对实体去重存储,统计频次,作为词典用于后续 jieba 分词。
def process_entity_frequencies(csv_file, output_file):
"""
从 CSV 文件中统计实体频次,并将结果写入文本文件
参数:
csv_file (str): CSV 文件路径
output_file (str): 输出文件路径
"""
entity_counter = Counter()
# 从 CSV 文件中读取数据
with open(csv_file, 'r', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile, delimiter='\t')
for row in reader:
if len(row) >= 3:
entity1 = row[0].strip() # 实体1
# 更新实体计数
entity_counter[entity1] += 1
# 将统计结果写入文本文件
with open(output_file, 'w', encoding='utf-8') as f:
for entity, frequency in entity_counter.items():
f.write(f"{entity} {frequency} n\n") # 添加自动计算的词频和固定的词性
# f.write(f"{'苹果'} {100} n\n")
print(f"实体及其词频已成功从 {csv_file} 写入 {output_file} 文件。")
知识图谱构建完成!
实体及其词频已成功从 apple_entities_relations.csv 写入 apple.txt 文件。
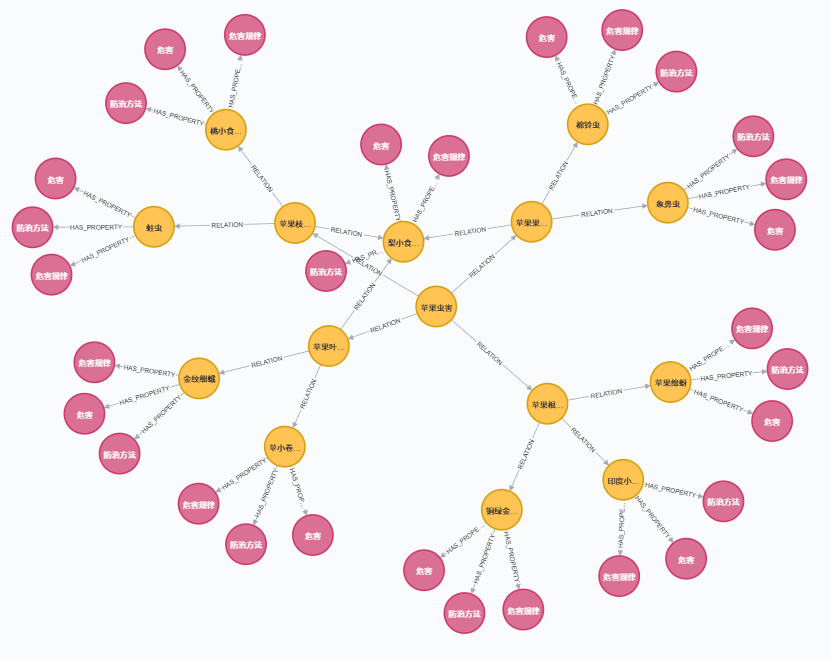
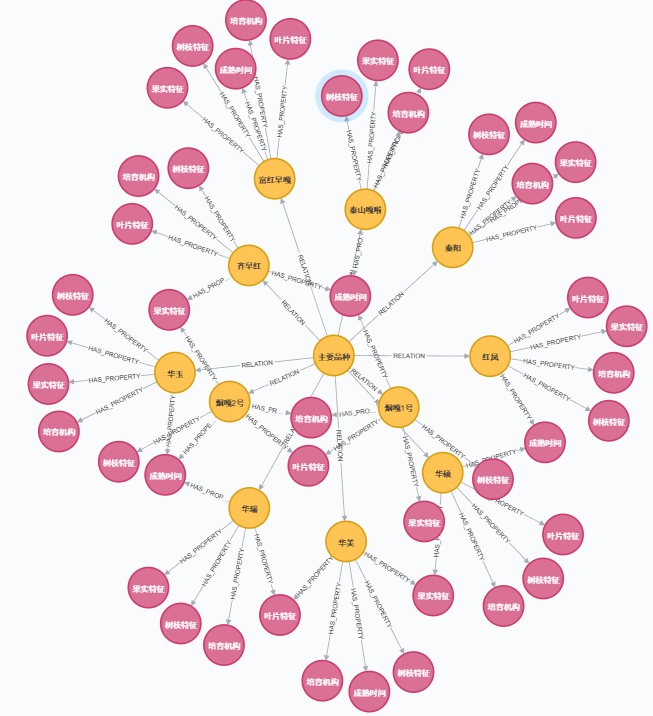
苹果叶部病害 6 n
苹果病害 4 n
主要品种 11 n
苹果白纹羽病 5 n
苹果裂果病 4 n
果锈 4 n
锈果病 4 n
苹小卷叶蛾 3 n
秦阳 5 n
泰山嘎啦 5 n
意图识别
代码首先通过 load_pretrained_model_and_tokenizer 函数加载预训练的模型和分词器,为后续的自然语言处理任务提供支持。接着调用 load_entities 加载实体集合,调用 load_templates 加载问题模板和查询模板,用于匹配和处理用户输入。用户通过控制台输入问题后,代码使用 process_user_question 函数结合模型、模板和实体集合,对问题进行解析,提取出用户意图和相关实体。
if __name__ == "__main__":
# 加载预训练模型和分词器
tokenizer, model = load_pretrained_model_and_tokenizer()
# 加载模板和实体
entities = load_entities()
question_templates, query_templates = load_templates()
# entities = load_entities()
# 用户输入
user_input = input("请输入你的问题:")
intent,category = process_user_question(user_input, tokenizer, model, question_templates, entities)
if category and intent:
print(f"用户提问分类结果:\n 实体: {category}, 意图: {intent}")
def load_pretrained_model_and_tokenizer(model_path="./bert-base-chinese"):
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertModel.from_pretrained(model_path)
return tokenizer, model
def load_entities(entity_file='apple.txt'):
entities = set()
with open(entity_file, 'r', encoding='utf-8') as f:
for line in f:
entity = line.split()[0] # 获取每行的实体名称
entities.add(entity)
return entities
def load_templates(question_template_path='templates/question_templates.json',
answer_template_path='templates/answer_templates.json'):
with open(question_template_path, 'r', encoding='utf-8') as f:
question_templates = json.load(f)
with open(answer_template_path, 'r', encoding='utf-8') as f:
answer_templates = json.load(f)
return question_templates, answer_templates
get_sentence_vector 函数接收输入句子、分词器(tokenizer)和预训练模型(model),将输入文本转化为张量格式,通过模型前向传播计算隐状态,并对所有 Token 的隐藏状态进行平均池化,生成句子向量(句子的固定维度表示),最终返回为 NumPy 数组格式。extract_entity 函数用于从一组单词(words)中提取指定实体(例如已知的苹果品种名称)。通过逐一检查单词是否属于指定的实体集合(entities),如果匹配则返回该实体,否则返回 None,表示未识别到实体。cosine_similarity 函数:用于计算两个向量之间的余弦相似度,首先将输入向量展平为一维,然后计算点积和向量的范数(模长),利用公式计算余弦相似度(向量夹角的余弦值)。如果输入向量中有零向量,返回 0.0,表示无相似度。
def get_sentence_vector(sentence, tokenizer, model):
inputs = tokenizer(sentence, return_tensors="pt") # 将输入文本转为 tensor 格式
with torch.no_grad():
outputs = model(**inputs)
hidden_states = outputs.last_hidden_state
# 对所有 token 进行平均池化,得到句子向量
return hidden_states.mean(dim=1).numpy()
def extract_entity(words, entities):
for word in words:
if word in entities: # 检查已知的苹果品种名称
return word
return None # 未识别实体
def cosine_similarity(vec1, vec2):
# 确保输入向量是1D
vec1 = vec1.flatten()
vec2 = vec2.flatten()
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
return dot_product / (norm_vec1 * norm_vec2) if norm_vec1 and norm_vec2 else 0.0
process_user_question 首先使用 get_sentence_vector 函数将用户输入转化为句向量表示,并通过 jieba 加载自定义词典对用户输入进行分词,同时动态提取分词结果中的实体。如果未识别到实体,函数会终止并返回 None。接着,通过遍历问题模板库,对每个模板生成句向量,与用户输入向量进行余弦相似度计算,找到与用户输入最匹配的意图类别(最高相似度对应的类别)。如果成功匹配到意图,函数返回最佳意图类别和提取到的实体;否则返回 None 并提示无法识别意图。
def process_user_question(user_input, tokenizer, model, question_templates, entities):
user_vector = get_sentence_vector(user_input, tokenizer, model)
jieba.load_userdict('apple.txt')
words = jieba.lcut(user_input) # 分词
print(f"分词结果: {words}")
# 动态提取实体
entity = extract_entity(words, entities)
if not entity:
print("未能识别实体。")
return None, None
# 意图识别
best_intent = None
highest_similarity = 0.0
# 遍历模板库匹配最佳意图
for category, questions in question_templates.items():
for question in questions:
# 获取模板的词向量
template_vector = get_sentence_vector(question, tokenizer, model)
similarity = cosine_similarity(user_vector, template_vector)
# 更新最优意图
if similarity > highest_similarity:
highest_similarity = similarity
best_intent = category
# 输出匹配结果
if best_intent:
# print(f"识别到的意图:{best_intent}")
return best_intent, entity
else:
print("未能识别意图。")
return None, None
输出:
请输入你的问题:花叶病怎么治疗?
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Lenovo\AppData\Local\Temp\jieba.cache
分词结果: ['花叶病', '怎么', '治疗', '?']
Loading model cost 0.347 seconds.
Prefix dict has been built successfully.
用户提问分类结果:
实体: 花叶病, 意图: 防治方法
进程已结束,退出代码为 0
图数据库搜索
answer = fetch_disease_info(
uri="bolt://localhost:7687",
user="neo4j",
password="123456",
disease_name="烟嘎2号",
attribute_type="成熟时间",
templates_path="templates/answer_templates.json"
)
print(answer)
fetch_disease_info 函数用于查询病害信息并基于模板生成格式化答案。函数接受数据库连接参数(uri、user、password)、病害名称(disease_name)、查询的属性类型(attribute_type)以及模板文件路径(templates_path)。首先,通过读取指定路径的模板文件加载模板,确保根据属性类型生成对应的格式化回答。接着,利用 GraphDatabaseQuery 类与 Neo4j 数据库交互,通过 query_disease_info 方法查询指定病害及其属性类型的相关信息。查询结果若存在,则将结果列表格式化为逗号分隔的字符串,并根据模板生成答案;若无结果,则返回模板中的默认提示信息。最后,无论查询是否成功,都通过 db_query.close()关闭数据库连接。
def fetch_disease_info(uri, user, password, disease_name, attribute_type, templates_path):
"""
查询病害信息并基于模板生成答案。
参数:
uri (str): 数据库连接 URI
user (str): 用户名
password (str): 密码
disease_name (str): 病害名称
attribute_type (str): 查询的属性类型
templates_path (str): 模板文件路径
返回:
str: 格式化的最终答案
"""
# 加载模板
with open(templates_path, "r", encoding="utf-8") as f:
templates = json.load(f)
db_query = GraphDatabaseQuery(uri, user, password)
try:
# 获取查询结果
result = db_query.query_disease_info(disease_name, attribute_type)
print(result)
# 根据模板生成答案
template = templates.get(attribute_type, "{}没有相关的{}信息。")
# 如果有结果,进行格式化
if result:
result_list = "、".join(result)
return template.format(disease_name, result_list)
else:
return template.format(disease_name, attribute_type)
finally:
db_query.close()
GraphDatabaseQuery 类用于与 Neo4j 数据库交互,实现针对病害信息的查询功能。通过 __init__ 方法初始化数据库连接,接收 URI、用户名和密码作为参数,并创建一个驱动实例以与数据库通信;close 方法用于关闭数据库连接,释放相关资源。核心方法 query_disease_info 通过接收病害名称(disease_name)和属性类型(attribute_type),执行针对性查询并返回结果。如果属性类型为“包括”,方法执行的 Cypher 查询会匹配病害与其关联实体的关系并返回实体名称;否则,方法将匹配病害节点与属性节点的关系,基于属性类型返回属性值。查询结果通过会话执行后,提取为一个值列表返回。
class GraphDatabaseQuery:
def __init__(self, uri, user, password):
# 初始化 Neo4j 图数据库连接
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def close(self):
# 关闭数据库连接
self.driver.close()
def query_disease_info(self, disease_name, attribute_type):
"""
根据病害名称和属性类型查询相关信息。
参数:
disease_name (str): 病害的名称
attribute_type (str): 需要查询的属性类型(如:防治方法、发病原因等)
返回:
list: 查询结果(如防治方法、发病原因等的值)
"""
with self.driver.session() as session:
# 根据 attribute_type 判断选择的查询模板
if attribute_type == "包括":
query = """
MATCH (d {name: disease_name})-[:RELATION]->(e)
RETURN e.name AS attribute_value
"""
else:
query = """
MATCH (d {name:disease_name})-[:HAS_PROPERTY]->(p:Property)
WHERE p.name = $attribute_type
RETURN p.value AS attribute_value
"""
# 执行查询并返回结果
result = session.run(query, disease_name=disease_name, attribute_type=attribute_type)
return [record["attribute_value"] for record in result]
输出:
['9月上旬']
烟嘎2号的果实成熟时间为:9月上旬
问答系统实现
代码实现了从知识图谱构建到用户问题处理与回答生成的完整流程。首先,代码配置了 Neo4j 数据库连接信息(NEO4J_URI、USERNAME 和 PASSWORD)以及文件路径(CSV_FILE_PATH 和 OUTPUT_FILE_PATH),并调用 build_knowledge_graph_from_csv 函数将 CSV 文件中的实体和关系数据导入 Neo4j 数据库,构建知识图谱;随后通过 process_entity_frequencies 函数统计实体频次并保存到指定文件中。接着,代码加载了预训练的 BERT 模型和分词器(tokenizer 和 model),以及实体和问题模板数据,用于后续的自然语言处理任务。用户输入问题后,通过 process_user_question 函数解析问题,提取出用户意图和目标实体分类结果(如实体类别和意图类型),并将这些信息传递给 fetch_disease_info 函数。该函数通过查询 Neo4j 数据库,结合回答模板生成最终的答案并打印出来。
import json
from collections import Counter
import jieba
import numpy as np
import torch
from neo4j import GraphDatabase
import csv
from transformers import BertTokenizer, BertModel
if __name__ == "__main__":
# 配置数据库连接信息和文件路径
NEO4J_URI = "bolt://localhost:7687"
USERNAME = "neo4j"
PASSWORD = "123456"
CSV_FILE_PATH = "apple_entities_relations.csv"
OUTPUT_FILE_PATH = "apple.txt"
# 调用主函数构建知识图谱
build_knowledge_graph_from_csv(CSV_FILE_PATH, NEO4J_URI, USERNAME, PASSWORD)
# 统计实体频次并写入文件
process_entity_frequencies(CSV_FILE_PATH, OUTPUT_FILE_PATH)
# 加载预训练模型和分词器
tokenizer, model = load_pretrained_model_and_tokenizer()
# 加载模板和实体
entities = load_entities()
question_templates, _ = load_templates()
# 用户输入
user_input = input("请输入你的问题:")
intent,category = process_user_question(user_input, tokenizer, model, question_templates, entities)
if category and intent:
print(f"用户提问分类结果:\n 实体: {category}, 意图: {intent}")
answer = fetch_disease_info(uri=NEO4J_URI,user=USERNAME,password=PASSWORD,disease_name=category,
attribute_type=intent,templates_path="templates/answer_templates.json"
)
print(answer)
知识图谱构建完成!
实体及其词频已成功从 apple_entities_relations.csv 写入 apple.txt 文件。
请输入你的问题:苹果的主要品种有哪些?
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Lenovo\AppData\Local\Temp\jieba.cache
Loading model cost 0.369 seconds.
Prefix dict has been built successfully.
分词结果: ['苹果', '的', '主要品种', '有', '哪些', '?']
用户提问分类结果:
实体: 主要品种, 意图: 包括
['秦阳', '泰山嘎啦', '华硕', '华玉', '富红早嘎', '红凤', '齐早红', '华瑞', '华美', '烟嘎1号', '烟嘎2号']
主要品种包括:秦阳、泰山嘎啦、华硕、华玉、富红早嘎、红凤、齐早红、华瑞、华美、烟嘎1号、烟嘎2号
请输入你的问题:褐斑病的症状有什么?
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Lenovo\AppData\Local\Temp\jieba.cache
分词结果: ['褐斑病', '的', '症状', '有', '什么', '?']
Loading model cost 0.375 seconds.
Prefix dict has been built successfully.
用户提问分类结果:
实体: 褐斑病, 意图: 病症
['叶片发病初期,正面出现黄褐色小点,逐渐扩大成褐色不规则病斑,边缘有绿色晕圈;后期病斑中央呈灰白色,边缘褐色,常出现同心轮纹状排列的小黑点。']
褐斑病病症有:叶片发病初期,正面出现黄褐色小点,逐渐扩大成褐色不规则病斑,边缘有绿色晕圈;后期病斑中央呈灰白色,边缘褐色,常出现同心轮纹状排列的小黑点。

文章评论