本文说明 GitHub Actions → 阿里云 ACR → SSH 生产机 Docker Compose 这条链路的实现步骤,以及近期改动的设计原因。
流水线如何实现
触发:main 分支 push,或 workflow_dispatch。
三阶段:变更检测 → 构建并推送镜像 → SSH 远端部署。
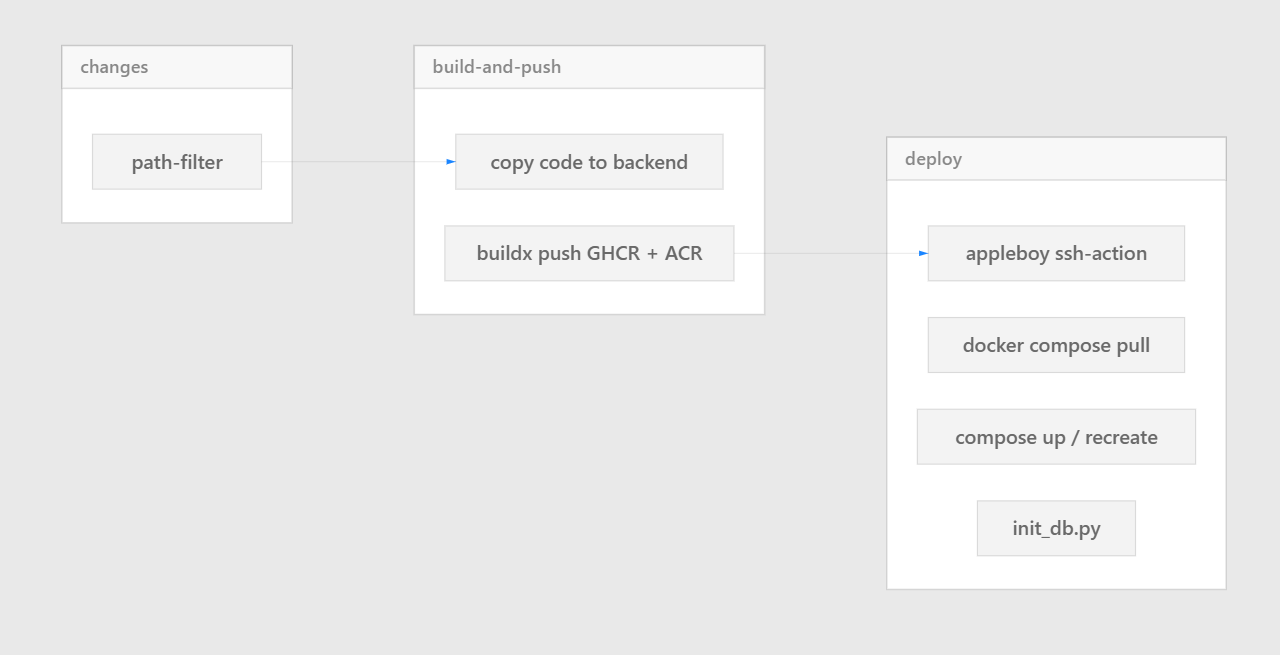
路径过滤
使用 dorny/paths-filter,输出与匹配规则:
| 输出 | 路径 |
|---|---|
backend |
backend/**、code/** |
frontend |
automata-web/** |
infra |
docker-compose.prod.yml、deploy/**,.github/workflows/deploy.yml |
原因:只对实际变更的镜像执行构建,缩短 CI 时间;code/** 归入 backend,保证训练脚本变更会触发后端镜像重建。
条件:至少一项为 true 才跑 build-and-push。deploy 在 build success 或 skipped 时仍会执行——因此部署脚本里的镜像 tag 策略必须与「本次是否构建」一致(见下文第二节)。
构建与推送
实现步骤:
cp -r ./code ./backend/code,与 Dockerfile 中COPY code/对齐,把train_model等脚本打进镜像。docker/build-push-action推送到 GHCR 与 阿里云 ACR,tag 为latest与${{ github.sha }}。- 使用 GHA
cache-from/cache-to加速层缓存。
原因:国内部署机从 ACR 拉取比直连 GHCR 更稳定;双 tag 兼顾「始终可拉的 latest」与「与提交一一对应的 sha」。
远端部署(SSH 脚本在做什么)
实现步骤(顺序执行):
cd到DEPLOY_PATH(来自 Repository VariableDEPLOY_PATH、deploy/DEPLOY_PATH文件或默认值)。- 用 GitHub API 拉取仓库
main上的docker-compose.prod.yml,保证生产 compose 与代码库一致。 - 参考注释 SQL:优先从配置的 OSS URL 拉取,失败则执行从 GitHub Release 拉附件的脚本(脚本本身也由 API 取到
/tmp)。 - 向
.env.prod写入/追加与 compose 约定的变量(如 Agent、参考数据挂载路径等)。 docker login阿里云 ACR。- 按 paths-filter 结果对 frontend / backend 执行
docker compose pull,再up或up --force-recreate;infra 变更时先down --remove-orphans再全栈up。 - 轮询等待 MySQL healthy 后,
compose run backend python init_db.py。 - 对前端、backend、download 端口做健康检查,
docker image prune -f。
实现细节:SSH 使用 appleboy/ssh-action@v1.2.0,command_timeout: 60m,避免大镜像 pull + extract 超时。
原因:部署目录里的 compose 由 CI 每次覆盖,避免手工漂移;先 pull 再 up,保证跑的是 registry 里的镜像;init_db 放在 MySQL 就绪之后,避免连接抖动导致 DDL 失败。
近期 CI/CD 改动的实现与原因
镜像 pull 不再使用 --quiet
实现:docker compose pull frontend / pull backend 去掉 --quiet,并打印说明(含大后端镜像耗时期望)。
原因:--quiet 会抑制层进度;后端镜像含 PyTorch 等,单层可达数 GB,无输出时易被误认为流水线挂死。保留完整输出便于确认仍在下载或解压。
部署时的 FRONTEND_IMAGE_TAG / BACKEND_IMAGE_TAG
实现:
- 若
build-and-push结果为 skipped:在 shell 中 exportFRONTEND_IMAGE_TAG=latest、BACKEND_IMAGE_TAG=latest,覆盖source .env.prod后可能残留的 SHA。 - 若本次有构建且
infra为 true:同时 export 前后端为${{ github.sha }}(因 infra 会触发前后端都打镜像)。 - 若仅有 frontend 或 backend 变更:只对对应变量 export 为
${{ github.sha }}。 - 日志中打印最终使用的两个 tag。
原因:skipped 时 registry 上不会有本次提交的 sha tag,若仍按 .env.prod 拉 sha 会出现 manifest unknown。仅 infra 变更时若只按「单端变更」export,容易与「实际推了两端镜像」不一致;显式在 infra 场景下两端对齐同一 sha,与 build 阶段行为一致。
infra 全栈重建后的固定容器名
实现:在 infra 分支里,docker compose down --remove-orphans 之后、up -d 之前,对 automata-frontend、automata-backend、automata-download-server、automata-mysql、automata-redis 依次执行 docker rm -f(不存在则忽略)。
原因:docker-compose.prod.yml 使用固定 container_name。若历史上用不同工作目录或 compose 项目名创建过同名容器,当前项目的 down 可能不会删掉这些容器,随后 up 会因「名称已被占用」失败。只删容器、不动数据卷,业务数据仍在挂载目录。
数据库初始化:压缩包、OSS 与挂载上的整条链路
要解决的核心问题:生产环境需要 业务表结构 + 大体积参考注释数据 一并就绪;注释库不宜打进应用镜像,又要避免每次部署重复下载、并在 MySQL 未稳定时跑 DDL 失败。下面从「把 SQL 弄到盘上」到「init_db 灌进库」写成一步接一步的实现,OSS、压缩包策略、Compose 挂载、init_db 顺序都是为同一目标服务。
把参考库以压缩包形式放到部署机(OSS 与 Release 回退)
部署 SSH 脚本通过 GitHub API 拉取 deploy/fetch-reference-sql-from-url.sh、deploy/fetch-reference-from-github-release.sh 到服务器 /tmp 并执行。
- 主路径:环境变量
REFERENCE_SQL_ARCHIVE_URL指向 HTTPS(生产上典型为阿里云 OSS 上的对象 URL;也可配 Secret/Variable,工作流里亦可设默认示例地址)。从该 URL 下载automata-reference-sql.tar.gz(名称由REFERENCE_SQL_ARCHIVE_NAME等变量约定)。 - 版本戳、避免白下:脚本请求 GitHub Release 附件元数据,与
REFERENCE_SQL_DIR(默认./data/reference_sql) 下.reference_bundle.meta中的stamp(附件 id 与 updated_at) 比对;未变则跳过整包下载。原因:参考包体积大,与「发新镜像」解耦;stamp 保证 Release 未更新时不浪费带宽与时间。需要强制更新时可设FORCE_REFERENCE_SQL_DOWNLOAD=1。 - 回退:OSS/URL 脚本失败时,再跑 Release 直连下载脚本,拉同名压缩包并同样写入/更新元数据。
- 解压落盘:包解压到
REFERENCE_SQL_DIR,供后续只读挂载进后端容器,作为 mysql 客户端导入的源文件目录。
为何强调 OSS:国内部署机从 阿里云 OSS 拉静态大包,通常比反复打 GitHub 更稳、更快;GitHub Release 作为第二源,保证 OSS 不可达时仍能完成「盘上先有 SQL 文件」这一步,否则后续初始化无从谈起。
Compose 挂载与「先 MySQL 再 init_db」的顺序
./data/mysql挂载为 MySQL 数据目录,业务库与已导入的参考数据持久化在此。./data/reference_sql只读挂到后端容器的/app/reference_sql,与.env.prod中REFERENCE_DATA_SQL_DIR=/app/reference_sql一致,使运行中的后端与 一次性init_db容器都能读到解压后的.sql/.sql.gz。
SSH 脚本在 docker compose up 之后轮询等待 MySQL healthcheck,再 sleep 一小段时间,然后执行 docker compose run --rm backend python init_db.py(在 backend/infra 相关变更时)。原因:避免刚就绪的连接抖动导致 OperationalError;init_db 内对建表失败还有有限次重试。
init_db.py 里具体做什么(业务表 + 参考注释表)
ensure_database_schema():创建业务侧表结构。ensure_reference_annotation_tables(engine)(reference_data/bootstrap.py):对参考注释表 建表/补列;若配置了REFERENCE_DATA_SQL_DIR且目标表行数为 0,则用mysql客户端从挂载目录导入对应.sql/.sql.gz。原因:大批量 INSERT 与日常 Alembic 迁移分离;仅空表导入,避免每次部署重复灌数。
与 ACR 的关系(运行载体)
参考 SQL 的初始化不依赖镜像内嵌数据,但执行 init_db.py 的仍是 从阿里云 ACR(及 GHCR 备份)拉取的后端镜像。镜像负责带齐脚本与 Python 依赖;磁盘上的 reference_sql + MySQL 卷负责带齐「要灌进去的内容」。两者在流水线里前后衔接:先 pull 应用镜像并 up,再按需拉参考包、解压、等库就绪、跑 init_db,共同完成「数据库初始化」这一件事。
小结
- 流水线:路径过滤 → 构建(含
code/打入后端镜像)→ 双注册表推送 → SSH 同步 compose 与 env → 参考 SQL 包按需拉取 → pull → compose 启停 → MySQL 就绪后 init_db。 - 体验与正确性:去掉
pull --quiet是为了可观测;tag 策略是为了拉取的镜像与本次是否构建、构建了哪些服务一致;infra 后rm -f固定名容器是为了固定 container_name 与 compose 元数据不一致时的可重复部署。 - 数据库初始化:OSS(主)+ Release(备) 把大压缩包落到
reference_sql目录;stamp 控制是否重下;挂载 + 等 MySQL healthy + init_db/bootstrap 完成业务表与参考注释表的建表与首次灌数;ACR 提供执行 init 的后端镜像,与参考文件分发解耦。
若后续引入 Celery Worker 等独立服务,在 compose 与同一 SSH 脚本中补齐对应的 pull 与 up 即可沿用同一套模式。

文章评论